(This blog post is a companion to the Digital Humanities 2018 Conference presentation titled “Legacy No Longer: Designing Sustainable Systems for Website Development” co-authored by Jessica Dussault and Greg Tunink)
View Slides | Ver en español a través de Google Translate
The Problem
The Center for Digital Research in the Humanities (CDRH) at the University of Nebraska–Lincoln has created and maintained dozens of research focused websites over the last 20 years. The majority of these sites use the Text Encoding Initiative (TEI XML) to mark up documents with human and machine readable metadata. The CDRH has over 30,000 TEI XML files, representing letters, newspapers, books, manuscripts, poetry, journals, magazines, etc. We also have data in CSV files, VRA Core files, and databases.
Several years ago, multiple tech team members of the CDRH started investigating replacements for Apache Cocoon, our framework for publishing TEI XML-based digital editions. Cocoon was still working fine, but wasn’t being updated, and the framework did not support new features. We wanted something that could work with other modern languages and frameworks. After a lot of research, mostly into frameworks written in Ruby, Python, and Java (node.js was still fairly new at the time), we settled on Ruby on Rails as a development platform going forward, due to its use on campus, in the library community, and the wide community outside of academia.
Challenges
An immediate problem presented itself: one of the big reasons we used Cocoon for so long is that it supported live transformations of TEI XML into HTML for display. These live transforms were very convenient, and there was no alternative in any highly used framework. Another challenge was that we didn’t want to just dump all past information into a new system without context. There is a strong desire in the community to maintain the context and unique properties of individual research sites. However, we are a small team tasked with keeping all past websites running (for now), and the preservation of files is outside our purview.
Throughout the framework research and development at the CDRH, we’ve arrived at a software philosophy:
- Keep it simple, stable, and sustainable
- Embrace modularity by writing software for one purpose
- Avoid over-engineering solutions (e.g. graphical interfaces where command-line will do)
- Provide comprehensive documentation
With this in mind, we set to work building a new system.
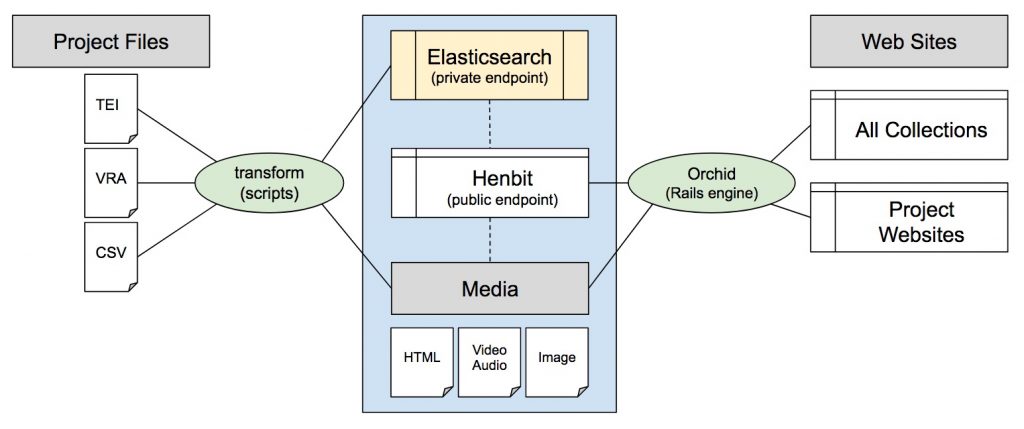
The Data Repository
Historically, CDRH project files were stored together in project folders. The TEI, scripts, and images would all be stored with the coding for the website, whether that was in PHP, Cocoon, or something else. Transformation scripts were duplicated project to project and also stored with the projects. This caused many problems with versioning, and these individual scripts would break with regular server updates.
As a solution, we created a regularized system for holding project data. Each project would have a “data repo” that held TEI, CSV, and other data, and these would sit in a larger framework that provided scripts for common actions (creating HTML, posting to indexes). You can see a list of these repositories on our CDRH GitHub page.
The general structure of a project data repo looks like this:
- authority_files – (optional) common authority files to be accessed during (TEI) transformation. New folders can be added arbitrarily as needed. (annotations, etc)
- config– hold public and private config files
- csv – a data folder
- output
- [environment] (development/production/other) Generally only production HTML is committed so we can track changes. The system allows for arbitrarily named environments, to cover use cases like providing different HTML files derived from the data formats
- es – temporary location to store and troubleshoot Elasticsearch ingest files
- html-generated
- solr – temporary location to store and troubleshoot Solr ingest files
- [environment] (development/production/other) Generally only production HTML is committed so we can track changes. The system allows for arbitrarily named environments, to cover use cases like providing different HTML files derived from the data formats
- scripts – collection of any scripts needed to individualize the indexing or HTML production for this particular project, building off of the main scripts
- tei – a data folder
Other data folders might include dublin_core or vra files.
Currently, our scripts mainly consist of:
- Ruby scripts to extract metadata and send to Elasticsearch
- XSLT scripts to extract metadata for Solr
- XSLT scripts to create HTML from TEI XML files
- Shell scripts to manage XSLT processing and indexing
The system is written to be extensible, so if we want to add new scripts for all the projects or only particular projects, we can.
Public and Private Endpoints: Elasticsearch Index and the CDRH API
The scripts in the previous step push metadata about the item to either a Solr or an Elasticsearch index. The Solr scripts exist to support older sites, but all new sites are created using the Elasticsearch index. By default, all new sites will be created to push to one Elasticsearch index, which will then provide data for the CDRH API (Powered by Henbit).
Through the API, we can power all other sites, including HTML display using the previously generated HTML snippets.
The API result format is based on the OpenAPI specification, and looks like this:
{
"req": {
"query_string": "/v1/collection/cather/items"
},
"res": {
"code": 200,
"count": 777,
"facets": {
},
"items": [
{
"identifier": "cat.let0001",
"category": "Writings",
"subcategory": "Letters",
"data_type": "tei",
"collection": "cather",
"uri_data": "https://cdrhmedia.unl.edu/data/cather-complete-letters/tei/cat.let0001.xml",
"uri_html": "https://cdrhmedia.unl.edu/data/cather-complete-letters/output/production/html/cat.let0001.html",
"title_sort": "helen louise stevens stowell (august 31, 1888)",
"title": "Helen Louise Stevens Stowell (August 31, 1888)",
"format": "letter",
"date_display": "August 31, 1888",
"date": "1888-08-31",
"date_not_before": "1888-08-31",
"date_not_after": "1888-08-31",
"publisher": "University of Nebraska–Lincoln",
"rights_holder": [
"Nebraska State Historical Society, Lincoln, NE"
],
"person": [
{
"name": "Stowell, Helen Louise Stevens",
"id": "0897",
"role": "addressee"
},
{
"name": "Boak, Rachel Seibert",
"id": "0105"
}
],
"recipient": [
{
"name": "Stowell, Helen Louise Stevens",
"id": "0897",
"role": "addressee"
}
],
"creator_sort": "Willa Cather",
"people": [
"Stowell, Helen Louise Stevens",
"Boak, Rachel Seibert"
],
"places": [
"Red Cloud, Nebraska, United States",
"Virginia, United States",
"Denver, Colorado, United States",
"Amboy, Nebraska, United States",
"Beatrice, Nebraska, United States"
],
"works": [
"Red Cloud Republican",
"Princess Napraxine (1884) Ouida"
],
"annotations_text": "Milton Metzger .... Your affectionate friend Wm Cather",
"on_this_day_k": "August 31",
"places_written_k": [
"Red Cloud, Nebraska, United States"
]
[View full query in the CDRH API]
A few notes about this (truncated) entry:
- category and subcategory are internal CDRH fields, used in many sites already as a way to provide structure
- uri_data will always link to the original data file (TEI XML, CSV, etc)
- uri_html will link to the canonical version of the HTML snippet, which in turn may contain links to images stored in our media location
- many fields have an _sort counterpart to make sorting easier
- in addition to date_display and date, we have included date_not_before and date_not_after to capture ambiguous dates. More work and thought may be needed re: dates, as some items contain multiple exact dates.
- people, places, and works allow for quick indexes. The person field holds more detailed information about individuals, including an internal id and a role. The role allows us to categorize people in any way that makes sense to the project
- Dynamic fields can be added to any entry to support advanced site features. Including _k and _text in the field name will map the fields to a keyword or text type field. In the above example, annotations_text supports a separate text search of annotations (which are pulled from a common file) and on_this_day_k is a keyword field that supports the “On this Day” feature of the Cather Letters home page.
The intent of CDRH API, when populated, is to support the easy creation of exhibit sites, since any arbitrary metadata can be added and the HTML of the resource is provided, which can be the trickiest part to handle for TEI XML-based sites.
Orchid (Rails engine)
Orchid is a Rails engine which connects Rails 5 applications and the CDRH API. Creating a new, searchable TEI XML-based website with Orchid is a relatively easy process: start a new Rails site, include the Orchid gem, and run a generator script which prompts for your website title and the collection(s) in the API to query before it rearranges files to facilitate site-specific customizations. Sites can lock to a version of Orchid to reduce fragility during updates.

Media Retrieval
In legacy sites, associated media lived inside the website directory. The Center has now created a standard URL path for media files. It will be easier to optimize serving specific file types with this common retrieval structure. In the near future, the CDRH will be implementing a IIIF image server to serve images of varying sizes and resolutions.
Current Implementation and Future Plans
Currently, the API is being used to power one fully launched site, The Complete Letters of Willa Cather, a project of the Willa Cather Archive (WCA) which will eventually make all of Cather’s known, accessible letters freely available. The rest of the WCA is not yet part of the Orchid-powered Rails site, but future plans include migrating the rest of the content in.
Several sites are under development which will be powered by the API. A project called Family Letters will be fully bilingual, so will require adding language switching capabilities to the API and Orchid.
Once a few more projects are in the API, we can start creating indexes that expose some of the connections we can’t currently see because materials are all separate. We could also use the API to push data elsewhere, such as a triple store for relationship information, so we can start to visualize our collections, or use it as a base to generate metadata for DPLA (which our collections are not currently in.)
Sustainability
We kept our system as simple as possible in order to ease development in the future. Many parts of the process could be switched out: Storage could be switched to Fedora, we could change the format of the data repos to match new file layouts such as the not yet developed Oxford Common File Layout (OCFL), or we could push all the data to some other CMS instead of using Orchid. The possibilities are near endless, and we will be keeping an eye on software developments and will likely switch if any could meet our needs.
A Note About Preservation
Though we are located in a library and all of us care about preservation, this system is not intended as a preservation method. It may act in tandem with preservation efforts by the library, and our work in organizing previously dispersed project files will make them easier to archive. We’ll continue to develop with an eye towards preservation by continuing to follow best practices for digitization, adopting common file layouts when possible, and prepping our files for long term preservation.
Links:
- CDRH Github
- CDRH API Endpoint | Henbit on Github
- CDRH Projects page | CDRH Nebraska Projects
- The Complete Letters of Willa Cather
Credits:
Thanks to Misha Coleman for slide translation help