[Originally posted by Karin Dalziel, Jessica Dussault, Greg Tunink, Laura Weakly, Brian Pytlik Zillig, January 5, 2017 on Github Pages]
Reformatting the HTML
The XSLT to transform the TEI into HTML was re-written, to allow for the changes from P4 to P5. We also added new features to the HTML, like terms you can hover on to find the regularized version or click on to go to a search for that term. This HTML is pre-generated at the time the index is populated.
Reworking the Design and Navigation
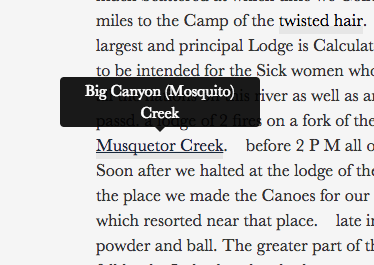
Since the initial design of the Journals of the Lewis and Clark Expedition in 2003, computer monitors have become bigger and more browsing than ever is now done on small mobile screens. Because of this, new best practices around navigation and site layout have emerged. In order to meet these best practices, we opted for a simplified navigational scheme and we dropped the sidebar navigation. New fonts were chosen, and the font size was set to a new, larger default.
The old site had used navigational flyout JavaScript which was not compatible with new browsers and was difficult to use, especially for low mobility users. With the new navigation, we simplified both the terminology and number of items in the main navigation, and made subpages clear and easy to follow.
| Old Navigation | New Navigation |
|---|---|
|
|
We used Bootstrap (v3) for the front end framework for the site, both because of compatibility across browsers and because it can seriously speed up development, useful when trying to design and launch a site in 6-8 weeks. Bootstrap contains by default CSS and HTML which we used to build many parts of the website, so we didn’t have to consider every element from scratch, nor did we have to reinvent the responsive design of the site. Bootstrap is also used widely around the internet, making it a familiar interface for users. One more advantage of Bootstrap is that it comes with handy features that make a site more useable on mobile devices and large screens alike.

When it came to the design, we looked closely at the original printed volumes, which informed font choice, color, and, of course, the distinctive “ribbon” element used along the top of the site. Color inspiration was also drawn from the original site. Soft, muted colors with high contrast were chosen for visibility and readability. Layouts were kept intentionally simple for readability.
Building the Site
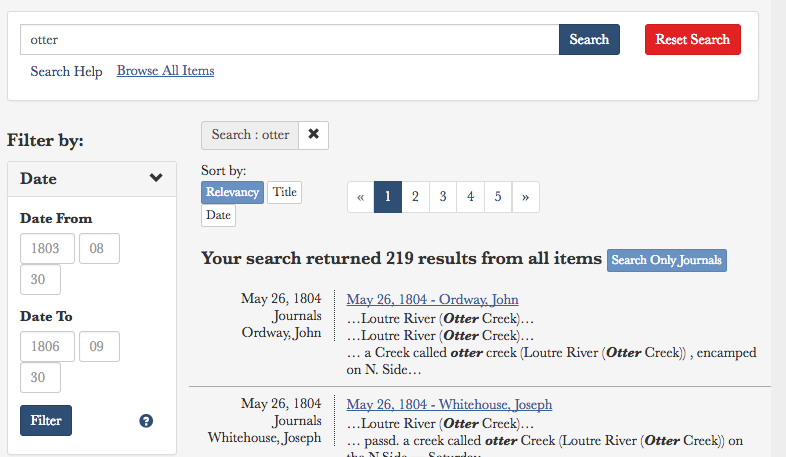
The new site is built with Ruby on Rails 5. Setup of the initial site was straightforward, thanks to previous work on creating a CDRH template involving a generic application and gems which parse requests and responses to Solr and build the views for pagination, sorting, and facets. Most of the time spent was in fine-tuning the search. Previously, the search was a whole site, full text search. While it could do stemming and boolean searches (which are supported by Solr out of the box) it did not allow any narrowing of results by date or author.
Our new search allows users to search the full text of the website and narrow by any or all of the following:
- Journal Entry or All
- Date
- Site section
- Author
- People, Place, or Native Nation mentioned
- Source (useful if you want to consult a print edition of the Journals, from the University of Nebraska Press)
We also improved the Journals index so a user can view all of the indexed terms, or limit by Native Nation, People, or Places. You can also sort the index alphabetically or by count.
Adding new ways to browse the 4284 journal entries has been a high priority for us. We added an interface to browse by calendar, which lets you jump to any date directly and preview who wrote entries on that day.

On individual date pages, we added a progress bar so you can see how far the explorers were on their journey.

In our multimedia section, we switched audio from Adobe Flash to HTML5 and uploaded higher quality versions of the files. We uploaded the videos to the University of Nebraska’s media sharing website, MediaHub, which also serves content via HTML5.
One component of the website proved easier to handle than its previous implementations: Unicode display. The original website was created when many glyphs beyond those found in ASCII were largely unsupported. The original Lewis and Clark site used image replacement to make all these characters legible. Thanks to the improvements in fonts and browsers, we can now display these characters as is.
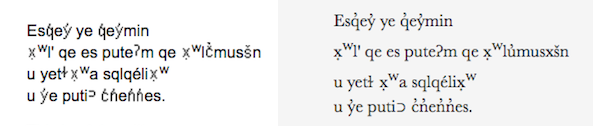
Rewriting Old URLs
Since the Journals of the Lewis and Clark Expedition website is cited frequently in publications both in paper and online, we wanted to make sure that older links still worked. This was more complex than it seemed at first, because there were multiple ways each page could be reached, and the URL rewriter had to account for all of them. We started this process by creating a spreadsheet of old and new filenames but discovered more URLs as we checked links throughout the old site and search engine results.

The URL rewriting rules are managed in a YAML config file so new ones can be easily added as we find broken links.
# Multimedia
-
method: r301
from: !ruby/regexp /^\/item\/(18.+kloefkorn.*?)(?:\.xml)?$/
to: /item/lc.mult.$1
-
method: r301
from: !ruby/regexp /^\/item\/lc\.(kloefkorn|video.+|white)(?:\.xml)?$/
to: /item/lc.mult.$1
-
method: r301
from: !ruby/regexp /^\/item\/(white.+?)(?:\.xml)?$/
to: /item/lc.mult.$1
We plan to update old links to the new ones as time allows, for example resubmitting to NINES, but at least links aren’t broken in the meantime. And, of course, links found in printed publications can still be reached.
- Introduction
- Part 1: Migrating XML and Building the Index
- Part 2: Building the Site
- Part 3: Future Goals