[Originally posted by Jessica Dussault, June 22, 2015 on Github Pages]
Linked Data. The Semantic Web. A lot of those terms have been rattling around in my brain for years, picked up from various digital humanities events and lectures. We started on a new project that hopes to use linked data to analyze relationships between hundreds of individuals. Theoretically, I understood what this meant, but practically I had absolutely no idea how to start implementing it.
I felt lost for a few days as I wallowed through lots of high level articles that all gave me the same introduction or as I got stuck in the details of software I never should have looked at to begin with. I even got briefly lost down a wikipedia rabbit hole of grammar when I looked up “predicate,” since that word comes up a lot in linked data. I felt like I was missing a page in the owner’s manual. Where was the “Quick Setup” chapter?

Okay, so what are RDFs and OWLs?
Great question! Think of a relational database. It can do a lot of things, but if you put a bunch of people into it and then asked “find everybody related to person A (and HOW they are related), then find everybody that is related to all of THOSE people, too (as well as the nature of their relationship)” it would get….complicated. This is where RDF shines.
RDFs (Resource Description Frameworks) use a model based on “triples.” Triples follow an object » predicate » subject format.
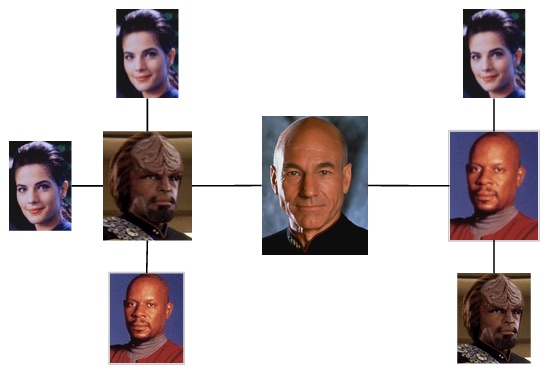
Sisko >> is on the show >> DS9
Sisko >> is rank >> captain
Picard >> is rank >> captain
Picard >> is on the show >> TNG
Dax >> is rank >> lt commander
Dax >> is on the show >> DS9

Dax >> served with >> Worf
Dax >> is married to >> Worf
Worf >> served with >> Dax
Worf >> is married to >> Dax
Picard >> served with >> Worf
Worf >> served with >> Picard
Picard >> has met >> Sisko
Sisko >> has met >> Picard
Dax >> served with >> Sisko
Sisko >> served with >> Dax
(etc)
Now you could ask a question like “Find all the people that Picard knows and then find all the people that THEY know (excluding the original person).” You would get something like the following from that query:
Picard | served with | Worf | served with | Dax
Picard | served with | Worf | is married to | Dax
Picard | served with | Worf | served with | Sisko
Picard | has met | Sisko | served with | Worf
Picard | has met | Sisko | served with | Dax

Of course, writing the triples doesn’t look nearly so nice as my arrow delineated examples above. Here is an example of what one entry from the Oh Say Can You See data looks like at this phase of the project.
An excerpt from an RDF file
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:oscys="http://server.unl.edu/rdf/oscys.owl#">
<rdf:Description rdf:about="http://server.unl.edu/rdf/oscys_test#per.000056">
<rdf:type>person</rdf:type>
<oscys:fullName>Queen, Louisa</oscys:fullName>
<oscys:sex>female</oscys:sex>
<oscys:childOf rdf:resource="http://server.unl.edu/rdf/oscys_test#per.000057"/>
<oscys:enslavedBy rdf:resource="http://server.unl.edu/rdf/oscys_test#per.000058"/>
<oscys:petitionerAgainst rdf:resource="http://server.unl.edu/rdf/oscys_test#per.000058"/>
<oscys:clientOf rdf:resource="http://server.unl.edu/rdf/oscys_test#per.000001"/>
<oscys:judgedBy rdf:resource="http://server.unl.edu/rdf/oscys_test#per.000004"/>
<oscys:judgedBy rdf:resource="http://server.unl.edu/rdf/oscys_test#per.000063"/>
</rdf:Description>
</rdf:RDF>
Well, okay, that looks way more complicated than the examples above. What it is really saying is the following:
person 000056 >> is a >> person
person 000056 >> is named >> Queen, Louisa
person 000056 >> sex is >> female
person 000056 >> is a child of >> person 000057
(etc)
It looks a lot more complicated because it is using a mixture of literals and resources. Literals are just straight up text and numbers. An example above is the person’s fullName: “Queen, Louisa.” Resources are the URIs that point at other entries in the RDF document (or even in other RDF documents). If you wanted to reference this particularly person, you would use the URI with #per.000056 on the end. You could have defined the references to other people are literals like “per.000004” but then the magic of linked data would be lost. Its power comes from knowing that the childOf relationship is one specific person and having access to the relationships and descriptions of that person as well. So perhaps the above translation would be more accurate if we said:
http://path#person000056 >> is a child of >> http://path#person000057
But wait, there’s just one more detail in the RDF that we can’t overlook. There is a namespace “oscys” before most of the lines describing the person. This namespace is defining the predicates. That is to say, one can write down “childOf” wherever they like but that doesn’t mean anything to a computer. In fact, it might not mean a ton to hu-mans like us out of context, either. All of those predicates can be described in what I have been thinking of as a schema file, but which the internet likes to call a “ontological” file. This is where OWLs come in.

<owl:ObjectProperty rdf:about="#parentOf"> <rdfs:domain rdf:resource="#Person"/> <rdfs:range rdf:resource="#Person"/> <owl:Inverseof rdf:resource="childOf"/> <rdfs:subPropertyOf rdf:resource="#familyOf"/> </owl:ObjectProperty>
To connect them up, just make sure that you’re referencing the OWL file at the top of your RDF file. In the example RDF file, you’ll see that it is assigned to the namespace “oscys.”
Let’s break down the OWL example:
#parentOf >> domain >> #Person
#parentOf >> range >> #Person
#parentOf >> inverseOf >> childOf
#parentOf >> subPropertyOf >> #familyOf
That means that now we know that anybody joined up as the oscys:childOf predicate will return an object that should be the oscys:parentOf the original person. We could also do a search for all the predicates that are #familyOf and use those results to find all family relationships for a single person. Pretty cool stuff, right?
Thus endeth the crash course in what kind of things RDF does. Next up, how to actually start running the queries!
- Figuring out RDF and SPARQL: Part I Triples
- Figuring out RDF and SPARQL: Part II Getting Set Up
- Figuring out RDF and SPARQL: Part III Some Queries